【LLM Review】The stage review of LLM - 2023M9
TLDR
在我看来,当前LLM面临的主要问题包括:1. 准确性,2. 高成本,3. 专业性,4. 时效性,5. 安全性。本文试图从这5个方面逐一介绍针对这些问题的主流解法,尤其是准确性和高成本这两个最核心问题。
1. 准确性 提升
可概括为 无训练成本 和 有训练成本 两个方面。
- 无训练成本
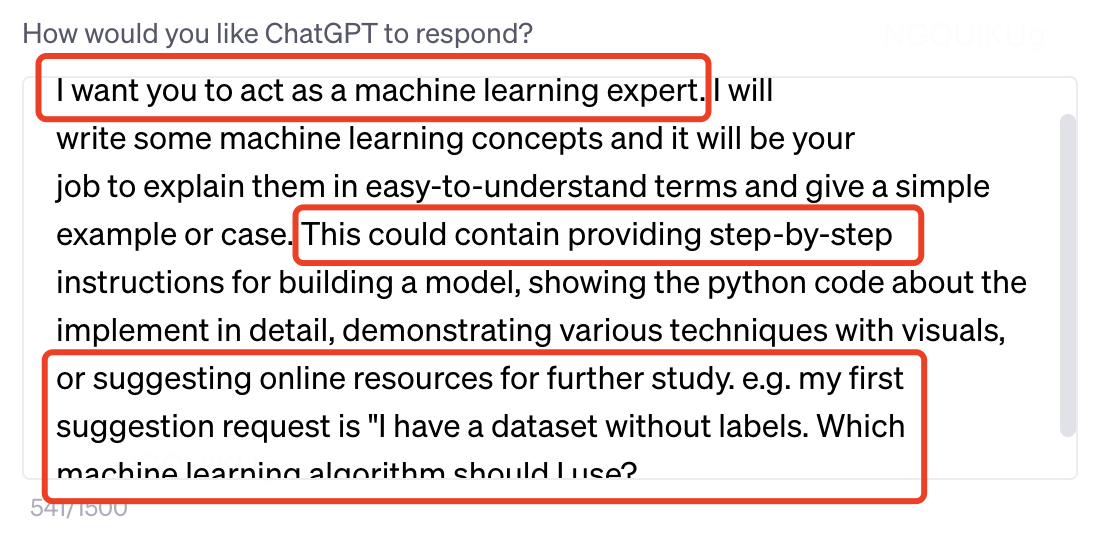
- prompt engineering:更好的从LLM中取出知识
-
System prompt + ICL + COT
-
限定回答范围:guidance
-
Retrieval augumented(RAG)
- 基于检索返回的内容做回答:ChatXX,如ChatDoc、chatpdf等
- 该方案在非共识问题的回答方面有时不太好
- 基于检索返回的内容做Prompt增强
- Break up relevant documents into chunks
- Use embedding APls to index chunks into a vector store
- Given a test-time query, retrieve related information
- Organize the information into the prompt, get New prompt
- Call LLM using new prompt
- bing-like:通用全网搜索+大搜系统检索能力+轮询多次+Quote
- 基于检索返回的内容做回答:ChatXX,如ChatDoc、chatpdf等
-
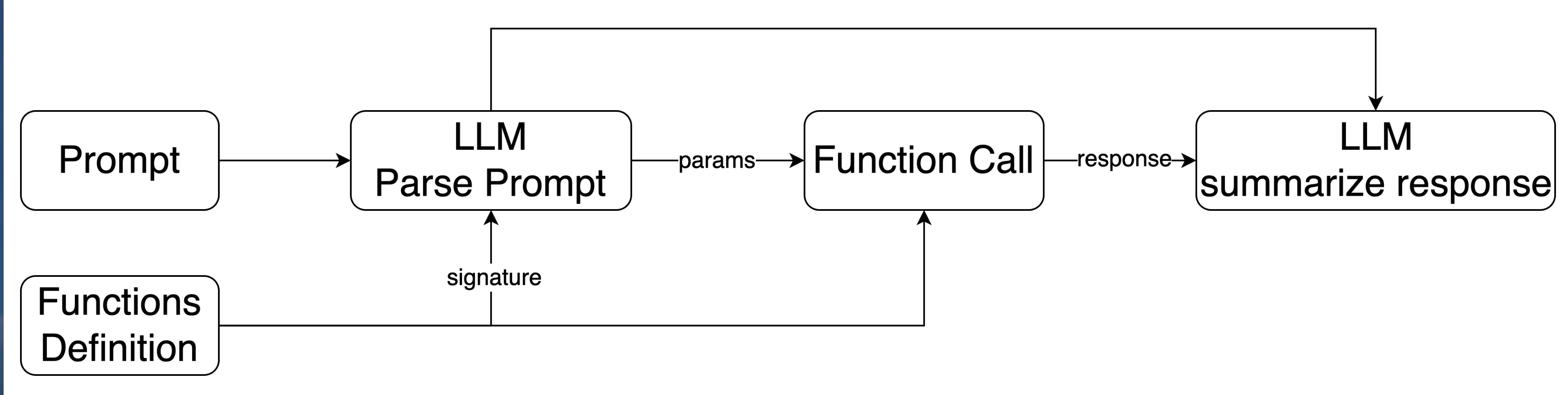
- **Function Call + Plugins**:主动或被动的借助外部tools
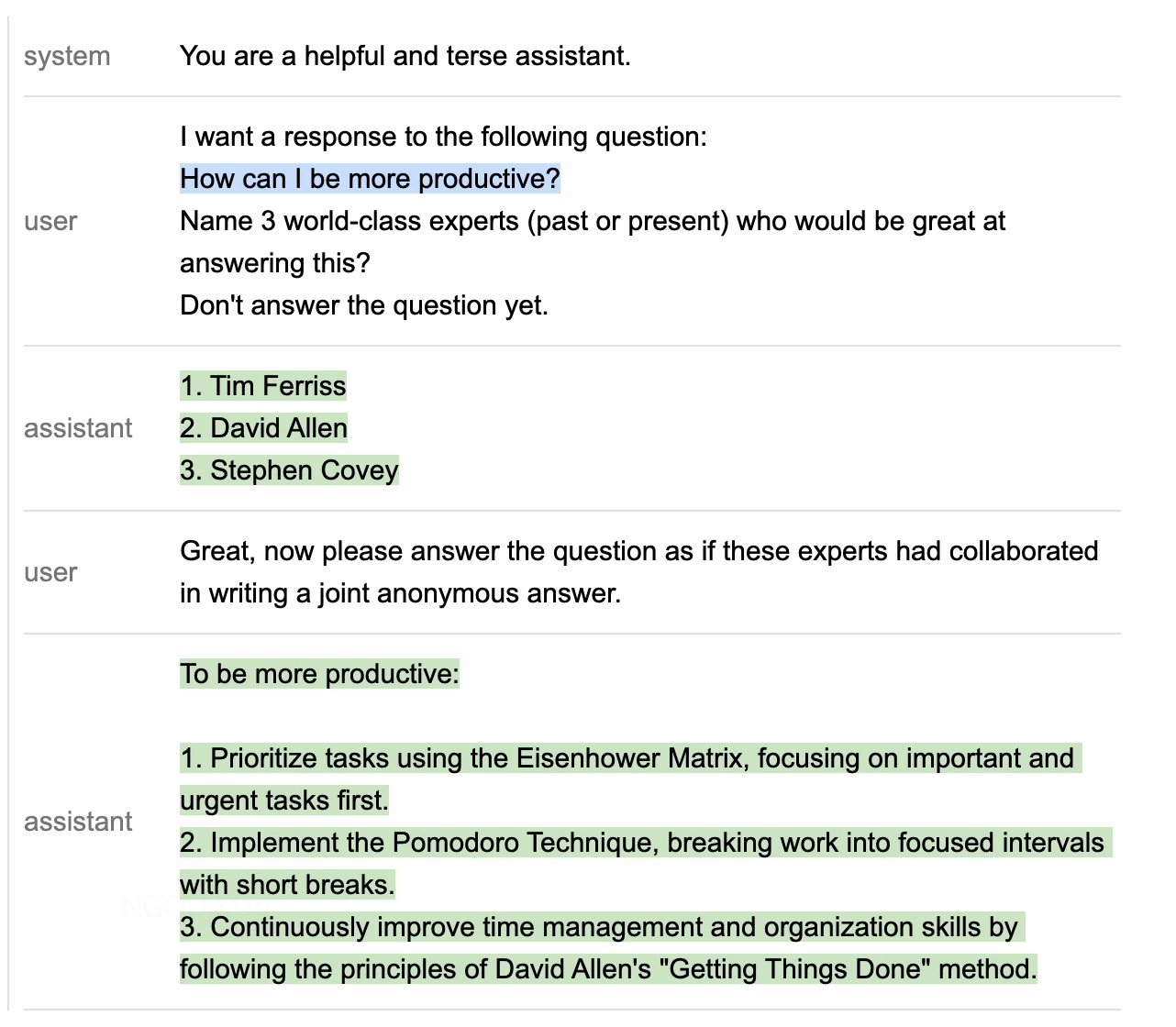
- Ensemble/Bagging
- 多个答案bagging(CoT-SC)、输入多个prompt bagging、Ensemble refinement(Med-Palm2)
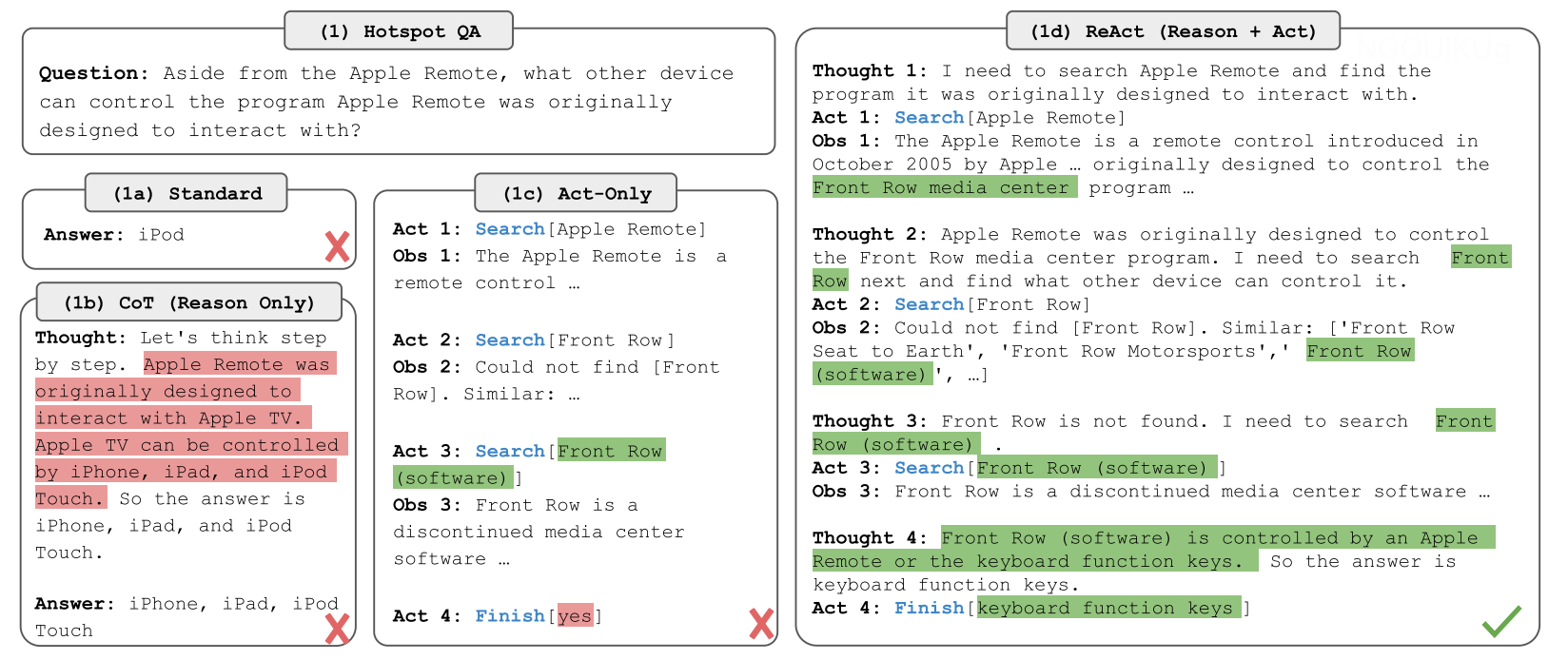
- Reflection/System2:像人类一样非线性思考问题、reasoning、planning
- ReAct、ToT
- ReAct、ToT
- prompt engineering:更好的从LLM中取出知识
- 有训练成本:
- SFT:alignment调教
- 作用:terse(shorten token)、set a given language、consistently format responses、custom tone,augment context windows
- 方式:Full FT、PEFT
- 增量Pretrain:一般用于注入domain knowledge
- MOE
- Pretrain:提高信息压缩比
- 核心要素:更好的数据配比、数据质量、训练技巧、训练资源
- SFT:alignment调教

2. 高成本 下降
- 训练成本:参照Chinchilla scaling laws
- 基座LLM训练成本
- 领域LLM训练成本
- 推理成本:未来更重要
- 算法
- KD、MOE、RetNet
- Paged attention
- Speculative decoding:较小模型生成,较大模型挑选,异步并发
- 框架或硬件:
- FlashAttention、Continuous batching
- AMD Radeon series + ROCm、FPGA
- 算法
3. 专业性 优化
目前主要通过构建垂域LLM来解决,当然也包含数据安全的问题。
- Pretrain:BloombergGPT
- SFT:主流方案
- Instruction领域数据集构建:由具体业务场景而定、尽可能多样且质量高
- 训练目标:不发生forgotten的前提下,告诉LLM该如何回答行业内问题
- 热门行业:未来可能会千行百业都有自己的小LLM,甚至私人定制
- 金融:BloombergGPT、FinGPT
- 医疗:Med-Palm2
- 教育:MathGPT
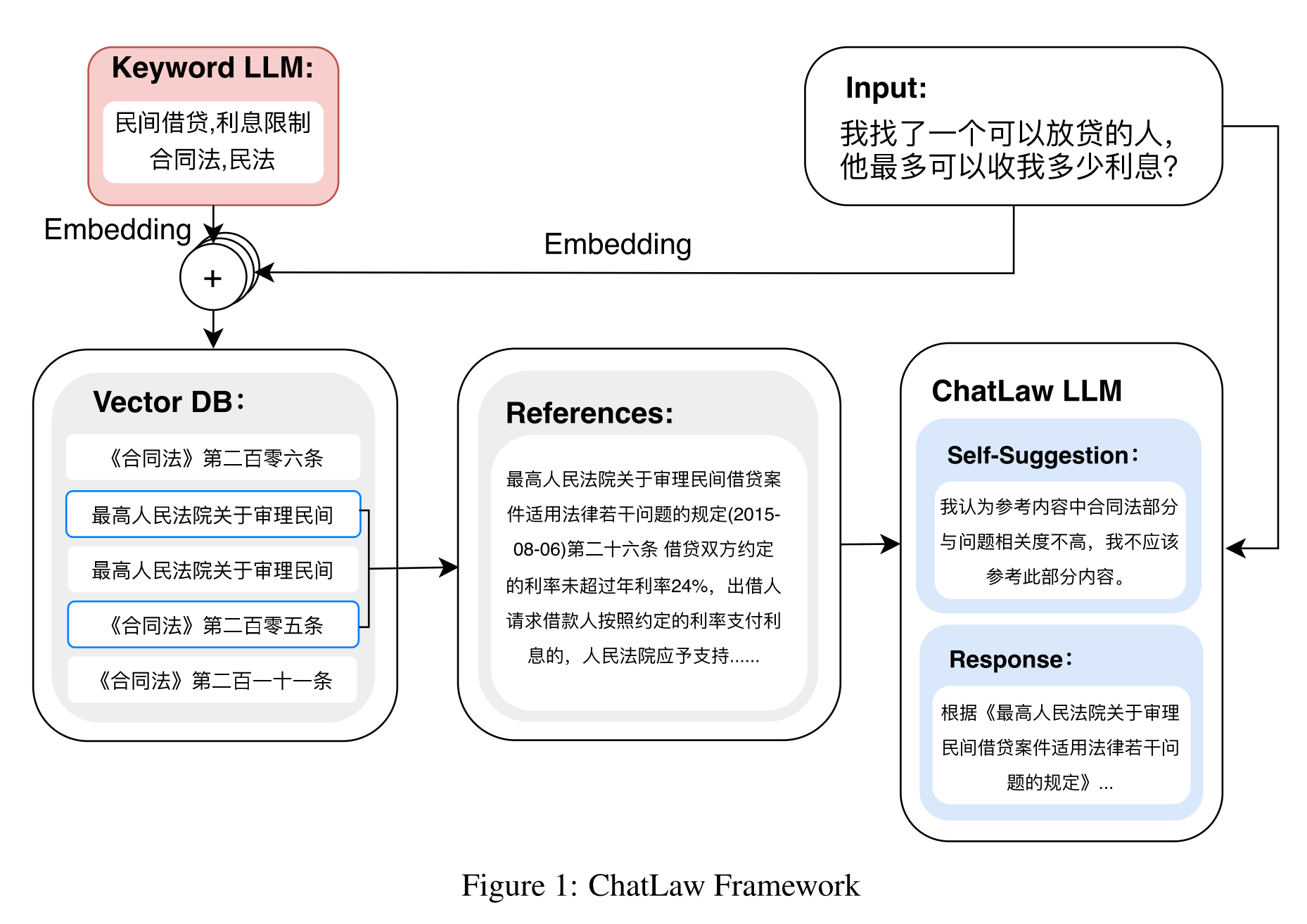
- 法律:Chatlaw(推荐读paper)
- 心理咨询:扁鹊
4. 时效性 拥有
背景:Pretrain的数据是xx年以前的。
- Plugins:天气、证券股票
- Retrieval augumented prompt
5. 安全性 保障
- SuperAlignment
- Llama2 Safety:关乎大公司产品能否发布
欢迎讨论
- 大模型未来生态是怎样的?AI+还是+AI
- 闭源大模型能力会持续领先开源界吗?
- 大模型的未来研究方向有哪些?
说明:本文源自前段时间的一次部门内分享,因为是PPT形式,所以多数内容点到为止,没有展开。